Rimo VoiceのAI検索を支える日本語議事録に特化したRAGアーキテクチャ
こんにちは。Rimoでエンジニアをしている宮﨑です。
今回は、Rimo VoiceのAI検索機能で十分な精度を出すために設計したアーキテクチャと検証結果について書きます。
RAGとは何か
Vanilla RAGの構成
RAGはRetrieval-Augmented Generationの略で、検索によって取得した外部のデータをLLMにコンテキストとして渡し、その内容を基に応答を生成する手法のことを指します。LLMが持つ知識は学習時点で固定されており、追加学習なしには更新できません。また、企業や個人に固有のデータは学習データに含まれないため、自社のドキュメントや会議の記録などを対象として質問応答を行いたい場合には、こうした仕組みが不可欠になります。
最もシンプルなRAG構成(Vanilla RAGと呼ばれる)は、ドキュメントを一定の長さでチャンクに分割し、それぞれをベクトル化してデータベースに保存しておき、ユーザーのクエリも同様にベクトル化して類似するチャンクを取得、その結果をクエリと共にLLMに渡すというものです。
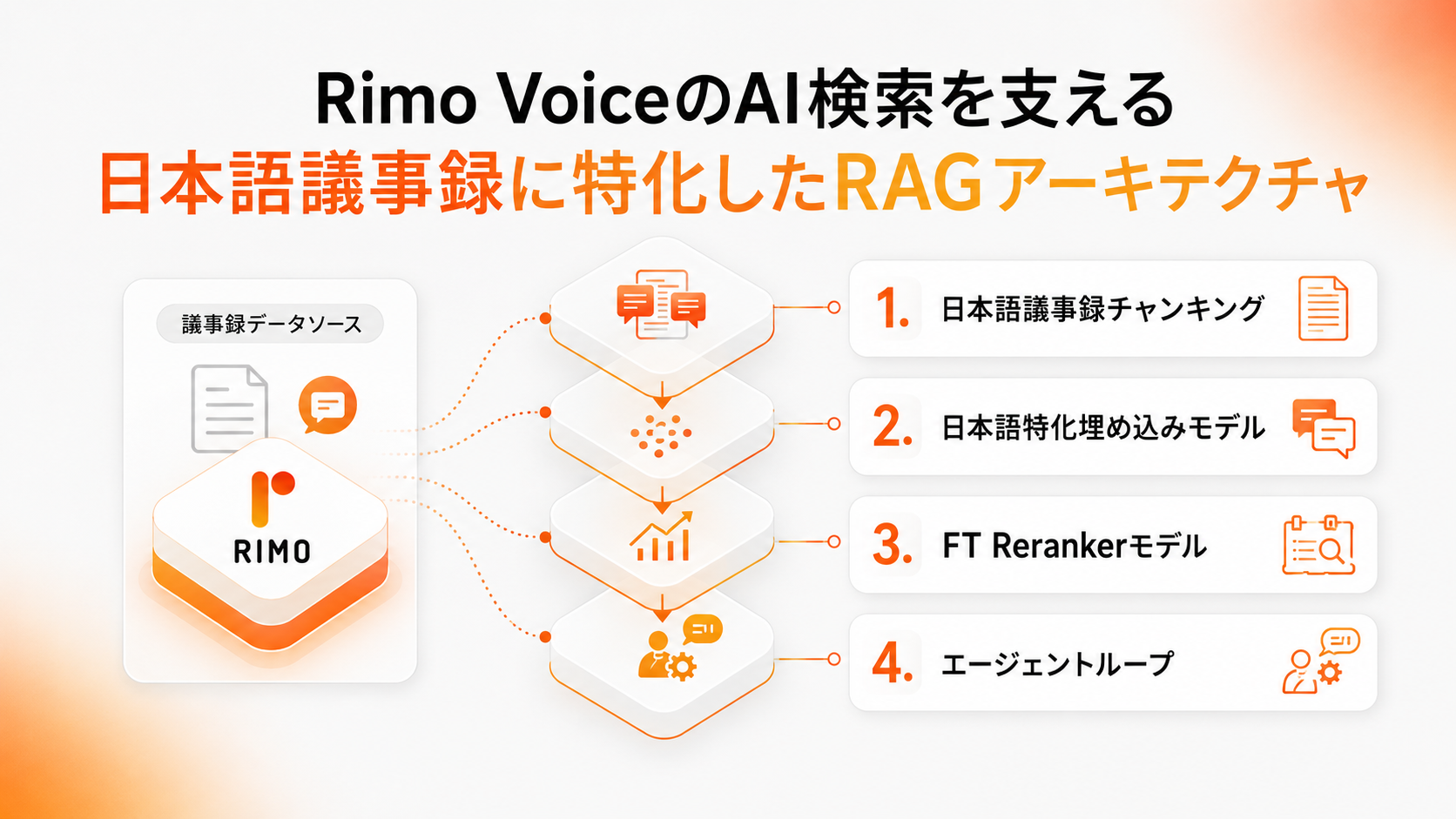
Rimoが採用したRAGアーキテクチャ
一般にRAGの弱点と言われるのは、データをチャンクで分けるため、(a) チャンク境界で文脈が途切れる、(b) 関連情報が複数チャンクに分散して網羅性が失われる、という2点です。この弱点を補うため、GraphRAGや階層型RAGのようにチャンク間の関係性をRAG内部に構造として持ち込むアプローチや、Self-RAGやCorrective RAGのように検索の要否や結果の妥当性を評価する機構をRAG自体に組み込むアプローチなど、さまざまなバリエーションが提案されてきました。
一方で、それらは本来RAGの外側で扱えることを、RAG内部に組み込もうとしているとも捉えられます。
前者の構造系については、RAGにおいて本質的に重要なのは、一回の検索でどれだけ関連度の高いチャンクを取得できるかという点にあると考えています。文脈の途切れや網羅性の問題についても、適切なチャンクさえ取得できれば、そのチャンクのメタデータを利用して前後のチャンクや関連ドキュメントを再検索することで補完可能です。そのため、チャンク間の関係性を複雑な構造としてRAG内部に保持する必要性は限定的だと判断しました。
また、後者の制御系についても、検索を含むツール呼び出しを判断するエージェンティックループを上位に置けば、検索の要否判断、クエリの書き換え、結果の自己評価、再検索といった振る舞いは近い形で実現できます。Self-RAGのreflection tokenやCorrective RAGの評価器のような専用機構を持たなくても、エージェントとして類似のループを構成することは可能です。
したがって、Rimoでは検索基盤そのものは最もシンプルなVanilla RAGを採用し、その外側にエージェンティックループを構築することで、複雑な振る舞いを担保する方針を取りました。つまり、検索構造としてはVanilla RAGですが、全体としてはAgentic RAGに近いアーキテクチャを採用しています。
検索精度の検証と改善
PoCでの精度検証
単純にVanilla RAGと言っても、データの前処理、チャンキングルール、埋め込みモデル・rerankerモデルの選定など、精度に直結する要素は様々あります。Rimoは議事録サービスであり、主な検索リソースは文字起こしとLLMで生成した議事録になるため、社内の2,400件の会議データを基にPoCの作成を行い、様々な条件で精度検証を行いました。
精度検証には26のクエリを用意し、模範解答に対して、一致、一部一致、不一致の3段階で評価を行いました。ここで分かったことには以下のような点が挙げられます。
このデータ量では埋め込みモデルによる精度差はほぼ観測されなかった
チャンクへのメタデータの入れ方によって精度が変わりやすい
議事録はRAGの精度を上げるのに有効なソースである
特に、議事録は情報密度が高くRAGのソースとして有効であることが示されました。実際に文字起こしのみ、議事録のみ、文字起こし+議事録の3条件で精度比較を行ったところ、文字起こし+議事録と議事録のみはほぼ同じ精度、文字起こしのみはそれらの75%程度の精度(3段階評価スコアの相対比)という結果でした。議事録は要約的に意味のまとまりを持つため、機械的な分割でも情報がチャンク間に分散しにくいことが、この結果の背景にあると考えられます。
rerankerモデルのファインチューニング
RAGの精度を向上させるうえでrerankerは欠かせない存在です。一方で、rerankerは「クエリとチャンクの関連度を出力する」という共通のインターフェースを持ちながら、各モデルが出すスコアの意味合いはモデルごとに大きく異なります。スコアの出力レンジ、分布の集中の仕方、クエリごとのスコアの変動幅などはモデルごとに異なり、汎用rerankerのスコアをそのまま絶対値の閾値として運用するのは難しいのが実情です。
そこでRimoでは、rerankerを汎用品として使うのではなく、議事録ドメインに合わせてファインチューニングすることで、スコア分布そのものを設計し直す方針を取りました。具体的には、関連度ラベルに対応した位置にスコアのピークが立つように学習させ、固定の閾値を「ハルシネーション抑制のための足切り値」として運用できる状態を目指します。
データセットの構築
学習データには、実際にRimo社内で使用されたクエリと取得チャンクのペアを使用しました。355クエリ、約7,000件のクエリ–チャンクペアを抽出し、各ペアにLLMで以下の3種類の関連度ラベルを付与しています。
ラベル | 内容 | 件数 |
|---|---|---|
明確に関係あり | クエリの主語と求める情報が両方ともチャンクに直接記載されている | 3,208 |
判断材料として使える | 直接の答えはないが、主語やテーマが一致しておりLLMが推測できる材料になる | 3,075 |
全く関係なし | 主語・キーワード・テーマのいずれも含まれない | 649 |
学習は、3カテゴリにそれぞれ連続値のスコアを割り当てて回帰問題として解くソフトラベル回帰の方針を採用しました。「明確に関係あり」を1.0、「全く関係なし」を0.0とし、中間ラベルに与える教師値をハイパーパラメータとして扱います。教師値を変えると学習後のスコア分布全体が変化し、固定閾値で運用したときに中間チャンクが足切りを通過する割合が変わります。教師値を高くするとLLMに流れる中間チャンクが増え、低くすると本来有用なチャンクまで落としてしまうというトレードオフがあるため、ここを通じて間接的に中間チャンクの通過率をコントロールできる、という設計です。日本語特化のrerankerをベースに、中間ラベルの教師値を振りながら、下流の検索精度と分布の分離が最良となる組合せを探索しました。
学習前後のスコア分布
学習前後でのラベル別のスコア分布図を以下に示します。

学習前のベースモデルは3カテゴリすべてのチャンクの多くが0近傍に張り付いており、ラベル間の分離がほとんどありません。これでは閾値をどこに置いても足切りが効きません。学習後は「全く関係なし」が低スコア帯、「判断材料として使える」が中間帯、「明確に関係あり」が高スコア帯にそれぞれピークを持つ三峰に分離し、閾値を1つ決めるだけで「明確に関係ありはほぼ通す/判断材料として使えるはコントロール/全く関係なしはほぼ止める」という運用が成立する状態になりました。一方で、rerankerのファインチューニングとしては7,000件は小規模であり、未知のドメインやクエリ表現に対する汎化、ラベル境界付近のスコア精緻化には今後改善の余地が残っています。
Retrieval評価:OSSフレームワークとの比較
RAGは一般に、作るのは簡単にできるが、精度向上は難しいと言われます。LangChainやLlamaIndexにはVanilla RAGを数十行で書ける枠組みが揃っているため、もしそれでRimoと同等の精度が出るなら、独自実装する意味は薄いということになります。
そこで、以下の構成を同じ26問で比較しました。本来は100〜200問程度のクエリを用意して比較すべきですが、ここではあくまで傾向を把握する目的で行います。
LangChain (default): RecursiveCharacterTextSplitter 1000字 + OpenAI embedding + Chroma + RetrievalQA
LangChain (チューニング版): 上記にBM25ハイブリッド (RRF) + Cohere reranker
LlamaIndex (default): SentenceSplitter 1024字 + OpenAI embedding + VectorStoreIndex
LlamaIndex (チューニング版): 上記にBM25ハイブリッド + Cohere reranker
Rimo: chunker + embedding + BM25/dense ハイブリッド + FT済み reranker
いずれも最終的にtop-10の検索結果を回答生成に渡す設定で揃えています。
評価指標:chunkレベルで「回答根拠を引けたか」を測る
議事録のような長文ドキュメントでは、1つの会議の中に複数のトピックが並びます。検索の単位は会議ごとのドキュメントですが、質問への答えはその中のごく一部の発言にしか含まれていないことが多く、たとえ「正解の会議」を検索結果に含めていても、その会議の中の答えに関係するchunkを上位に持ってこられていなければ、LLMは答えを作れません。
したがって評価はchunkレベルで行います。具体的には、「ユーザーの質問に対する模範解答を作るのに必要なchunkを、検索結果の上位K個にどれだけ含められたか」を以下の指標で測ります。
chunk recall@K: 必要なchunkのうち何%を引けたか
chunk hit@K: 必要なchunkが上位K個に1つでも含まれているか
chunk MRR: 最初の必要chunkが何位にあるか
ここでいう「必要なchunk」を、本記事では根拠chunkと呼びます。

根拠chunkの集合はLLM-as-judgeで作りました。質問・模範解答・候補chunkのテキストを渡し、「このchunkの内容は模範解答の少なくとも1つの主張・事実の根拠になっているか」を0/1で判定させます。chunkerが違うとchunkの集合自体が違うため、各stackのchunkerで正解の議事録を分割し直し、それぞれ独立に根拠chunk集合を作りました。
評価結果と考察
結果が下表です。
stack | chunk recall@10 | chunk precision@10 | chunk hit@10 | chunk MRR |
|---|---|---|---|---|
LangChain (default) | 0.172 | 0.096 | 0.423 | 0.231 |
LangChain (チューニング版) | 0.176 | 0.104 | 0.462 | 0.327 |
LlamaIndex (default) | 0.247 | 0.150 | 0.538 | 0.321 |
LlamaIndex (チューニング版) | 0.273 | 0.162 | 0.577 | 0.481 |
Rimo | 0.391 | 0.292 | 0.808 | 0.647 |
Rimoは全4つのOSS構成に対してchunk hit@10で+23.1pt〜+38.5pt上回りました。OSSの中で最も強かったLlamaIndex (チューニング版)に対しても、chunk hit@10で+23.1pt、chunk recall@10で+11.8ptの差があります。
興味深いのはLlamaIndexがLangChainを上回る傾向がはっきり出ている点です(chunk hit@10で+11.5pt)。両者とも同じembedding(OpenAI)・同じrerankモデル(Cohere)を使っていますが、LlamaIndexのdefault設計はnodeのmetadata(タイトルなど)をembedding入力に自動で混ぜる挙動を持つため、会議のタイトルが暗黙的にembeddingに乗ったことが効いていると考えられます。OSSを選ぶ場合でもフレームワーク選択が精度に効くことが分かります。
一方でチューニング版であってもRimoとの差は埋まりません。これはrerankerやhybridを足す工夫では追いつけない、議事録に特化したチャンキング戦略、日本語特化embeddingとFT済みrerankerが複合的に効いていると考えられます。

単発の検索精度としては、OSSの全構成を上回る水準に到達しました。一方で、RAGを実用に乗せるうえでは検索精度だけでは解決できない課題が残ります。具体的には、(a) 網羅性が必要な質問に対しては1回の検索では足りず、複数視点での検索や再検索が必要になること、(b) 検索を繰り返すとコンテキストが肥大しコスト・速度の問題が顕在化すること、の2点です。これらを扱うために、検索の外側にエージェンティックループを構築しました。
エージェンティックループの設計
速度と網羅性の両立
エージェンティックループの設計方法は、どのようなUXを提供したいかによって大きく変わる部分です。
例えば、コーディングエージェントでは、多少時間がかかってでも高精度なアウトプットを返すことが重視されます。そのため、十分な結果が得られるまで繰り返しツールを呼び出し、長時間にわたって調査を行うように設計されていることが一般的です。
一方で、RAGの主な用途は検索であり、ユーザーは質問後すぐに適切な回答が返ってくることを期待しています。そのため、RAGでは高速に応答し、短時間で回答を返すことが重要な要件になります。もっとも、すべての質問に対して即時性だけが求められるわけではありません。「~~とのこれまでのやり取りをまとめて」や「~~について全て列挙して」といったケースでは、一定の網羅性や精度が求められる場合もあります。
したがって、
少ない検索で応答を即座に返して速度を担保する
複数回検索を行って網羅性と精度を担保する
という2種類の要件を満たすように設計を行うこととしました。
コスト最適化
実際のエージェンティックループを設計する前に、もう一つ考えておく必要があるのがコストの問題です。RAGは通常、検索によってコンテキストが膨れ上がるという問題を抱えています。
例えば1つのチャンクが1000文字であった場合、上位20個の検索結果をLLMに渡しただけで2万文字のinputになってしまう上に、それらの中には無駄なチャンクも含まれていることが多いです。愚直に検索を繰り返してその結果を渡していると、数回のやり取りであっという間にトークンを食いつぶすことになりかねません。
これに対処するために、以下のような対策をとっています。
安価なモデルを使用する
コンテキストを圧縮する
検索結果の精度を高めて検索数を少なくする
OpenAIのmini系列やGeminiのflash系列など、安価なモデルを使用することで、そもそものコストを抑えることはできます。一方で指示追従性が落ちるなどの欠点もあり、この問題への対処は後述します。
より根本的な解決策は、コンテキストを圧縮することです。例えば別の検索で同じチャンクが引っ掛かった場合は、重複した検索結果を保持することになるので一方の結果のみを残すことができます。さらに、すでに検索結果を基にLLMが回答した後では、LLMが検索結果の中から必要なチャンクを選定しているため、不要と判断されたチャンクは現在の回答のコンテキストとしては不要であり削除できます。
上に挙げた二つの圧縮方法は、どちらも無駄なコンテキストを削除するという考えに基づいています。一方で、もう一度RAGの用途を考えてみると、あくまでも検索が主であり、長いやり取りにおいて過去の検索結果がずっと残っていることが必須であるとは限りません。そこで、必要なら再検索するという前提のもと、一定のターン数経過した検索結果は全て削除するようにしました。これはより大胆な方法ですが、RAGという用途だからこそ取り得る方法と言えます。
最後に、より根源的には、確度の高い検索結果を必要な分だけLLMに渡すことそれ自体が最良のコンテキスト圧縮と言えます。これまで述べたように一回の検索における精度の問題については一定取り組んでいるため、ここでできることはいくつの検索結果をLLMに渡せばよいかということになります。
これを算出するため、618件のクエリを基に、検索結果の各チャンクのスコアとLLMが実際に回答で引用したチャンクを突合して、引用されたチャンクが何位だったかを集計しました。top_20で引用されたチャンクの集合を100%(ベースライン)とし、top_kを小さくしていった時のカバー率が以下の通りです。
top_k | カバー率 |
|---|---|
20 | 100.0% |
15 | 90.5% |
10 | 72.5% |
7 | 55.9% |
5 | 42.7% |
この結果に加え、引用されたチャンクがクエリに関係するものだったかどうかの評価も踏まえて、最終的にtop_15をLLMに渡す設定としました。なお、この分析はあくまで「top_20の範囲内に正解があった」ことを前提にしているため、そもそもtop_20の外に存在する真に必要なチャンクは見えていない点には留意が必要です。
以上のような取り組みにより、RimoのRAGは一回の検索のコストを0.5〜2円程度(クエリの種別や検索回数による幅)に抑えることを実現しています。
安価モデルのハンドリング
検索するツールだけ渡しても、LLMがうまく検索してくれるかどうかは別問題です。Claude Opus 4.7やGPT-5.5に代表されるような最近のLLMは指示追従性や推論能力が高く、必ずしも細かく検索の仕方を指示することが最善ではないかもしれません。一方で、RimoのRAGは安価モデルを使用しており、さらに応答速度を速めるためにthinkingをほぼ無効化しています。このような条件では、LLMが「よしなに」動作してくれることを期待するのはかなり難しいです。
「速度と網羅性の両立」で述べたように、クローズドクエスチョンなど即座に回答を出してほしい場合と、時間がかかっても良いからより網羅的にもしくは正確性をもって回答してほしい場合があります。一方で、プロンプトを工夫してもthinkingをほぼ無効化している場合は、これら二つを適切に判断し、後者では十分にツールを繰り返し使用させることが、試行の範囲では難しいことが分かりました(詳細は後述のColumnを参照)。
そこで、adaptive thinking(クエリの性質に応じてthinking予算を可変にする仕組み)を採用し、通常はthinkingを無効化しつつ、より高度な検索ハンドリングが必要なクエリではthinkingを有効化するように切り替えることにしました。また、thinkingをほぼ無効化している場合はプロンプトの指示をより具体化することで安定した出力を得られるようになりました。
Column:LLMによるフィードバックループでのプロンプト改善は有用なのか
プロンプトの改善にはLLMによるフィードバックループも試しました。1回の検索のみで回答をした場合のヒット率は10%というクエリに対して、適切なプロンプトを組むことでLLMに再検索を促し、どの程度ヒット率が改善するかを検証しました。なお、この検証ではClaudeに自由に試してもらうために、途中途中での方針変更以外は何も指示を与えていません。
まず、Claude Opus 4.6は、「必ず再検索しろとプロンプトで強く指示すれば再検索する」という前提のもと、再検索条件の明示やfew-shotを試しましたがヒット率は改善せず、さらに指示が強すぎた結果、LLMが解答自体をやめて空文字を返してくる問題が生じました。そこで、7回目のイテレーションからは「再検索させるのではなく最初から複数の視点で同時検索させる」という方針のもとプロンプトを改善し始めましたが、こんどは評価対象にしていたクエリに依存したプロンプトを書くようになり、ヒット率は50%を達成したものの、全く汎用として使えないプロンプトになりました。
LLMによるフィードバックループでの改善は何度か試したことがありますが、いずれも特定のusecaseに過学習してしまうという問題にあたりました。今回の改善でも最終的にLLMによる自動改善は収束に至らず、自分で解決策を出すことになりましたが、プロンプトを改善するだけではなかなかうまく行かないということが分かったのは1つの収穫でした。指示の与え方を変えればうまく行く可能性もあるので、今後の課題と言えるでしょう。
e2e評価:Claude Codeとの比較
ここまではRAG内部の構成差による精度比較を行ってきましたが、最近ではgrepやReadといった汎用ツールを繰り返し呼び出すエージェント方式が、コーディングタスクを中心に広く実用化されています。コードベースには関数名・型名・ファイル名といったキーワード的な手がかりが豊富にあり、grepによる反復探索が効きやすいドメインだと言えます。
一方で、議事録は同じ概念が話し手ごとに異なる表現で語られ、トピックを示す決まった見出しも存在しないため、キーワードマッチに頼った探索は効きづらいドメインです。専用の検索パイプラインを持つRAGと、Claude Codeのような汎用ツールベースのエージェント方式とで、こうしたドメインにおいて実際にどの程度の差が出るのかは、検証する価値のある論点だと考えました。
そこで、PoC段階で使用していた約2,400件の会議データを基に、前章までと同じ26問のクエリについてClaude Code (Opus 4.7) を用いて回答を生成しました。Claude CodeはRAGのような専用パイプラインを持たず、ファイルシステムへのgrepやReadといった汎用ツールだけを与えて、エージェントとして自由に調査・回答を組み立てさせる方式です。なお、この検証は正確性を担保するものではなく、あくまでも傾向を調査するものです。
評価設計
評価のセットアップは前章までと同じです。回答の品質はLLM-as-judge(GPT-5.5)に5段階(0.00 / 0.25 / 0.50 / 0.75 / 1.00)で採点させ、結果のブレを抑えるためにn=3で中央値を取りました。また、判定基準は、正解の主要要素(事実・数値・固有名詞)をどの程度含むかと、それらに矛盾する記述があるかどうかにしました。Note-hitについては、Rimoは検索結果に含まれる会議で、Claude Codeは回答中で参照したファイルで判定し、いずれも「正解の会議が含まれていれば1」としました。
評価結果と考察
stack | Note-hit | Answer Correct (mean) | Answer Correct Rate (≥0.7) |
|---|---|---|---|
Claude Code | 0.808 | 0.779 | 0.731 |
Rimo | 0.808 | 0.731 | 0.692 |
正解の議事録を引けたか(Note-hit)は両者ともに21/26で完全に並びました。回答品質はClaude Codeがmeanで+4.8pt、Rate(≥0.7)で+3.9pt上回りました。クエリ単位で勝敗を取るとClaude Codeが9勝、Rimoが5勝、引き分けが12問という分布で、N=26という規模では統計的な有意差は判定しがたく、両者の品質帯はおおむね重なっています。
回答品質では平均で+5pt程度Claude Codeがやや上回るという結果でしたが、プロダクションのRAGとして見た場合の評価は変わります。Claude Codeは1つの回答を生成するのに数分を要しますが、RimoのRAGの場合は数秒から30秒程度(クエリの複雑さや検索回数による)であり、コストも低いです。またこの検証は2,400件の議事録データを基に行いましたが、本番環境のRimo社内のデータは80,000件以上に及びます。RAGはデータ量が増えてもクエリ時間の増加はほぼ観測されず、この規模でも実用的なレイテンシを維持して運用ができています。短時間かつ低コストで回答を生成できるという点で、RimoのRAGは十分実用的であると言えるでしょう。